Webapplicaties worden steeds interactiever en beginnen meer te lijken op native programma’s waarbij wachttijden en opnieuw laden niet meer nodig zijn. Bij grotere platformen brengt dit een aantal uitdagingen met zich mee. Deze platformen bestaan vaak uit meerdere geïsoleerde losstaande applicaties die met elkaar kunnen communiceren. Voorheen werd deze communicatie gedaan via inefficiënte synchronisaties en import processen waarbij 90% van de data onaangepast bleef, waardoor er dus een gigantische overhead ontstond.
Naast dat deze overhead een doorn in het oog is, zijn er nog wat nadelen te noemen:
• Data loopt tijdens het draaien van een sync of import al achter
• Relatief veel resources nodig om data te verspreiden binnen een platform
• Processen die van elkaar afhankelijk zijn duren onnodig langer
• Eindgebruikers lopen tegen wachttijden aan of zien verouderde informatie
Een alledaags voorbeeld
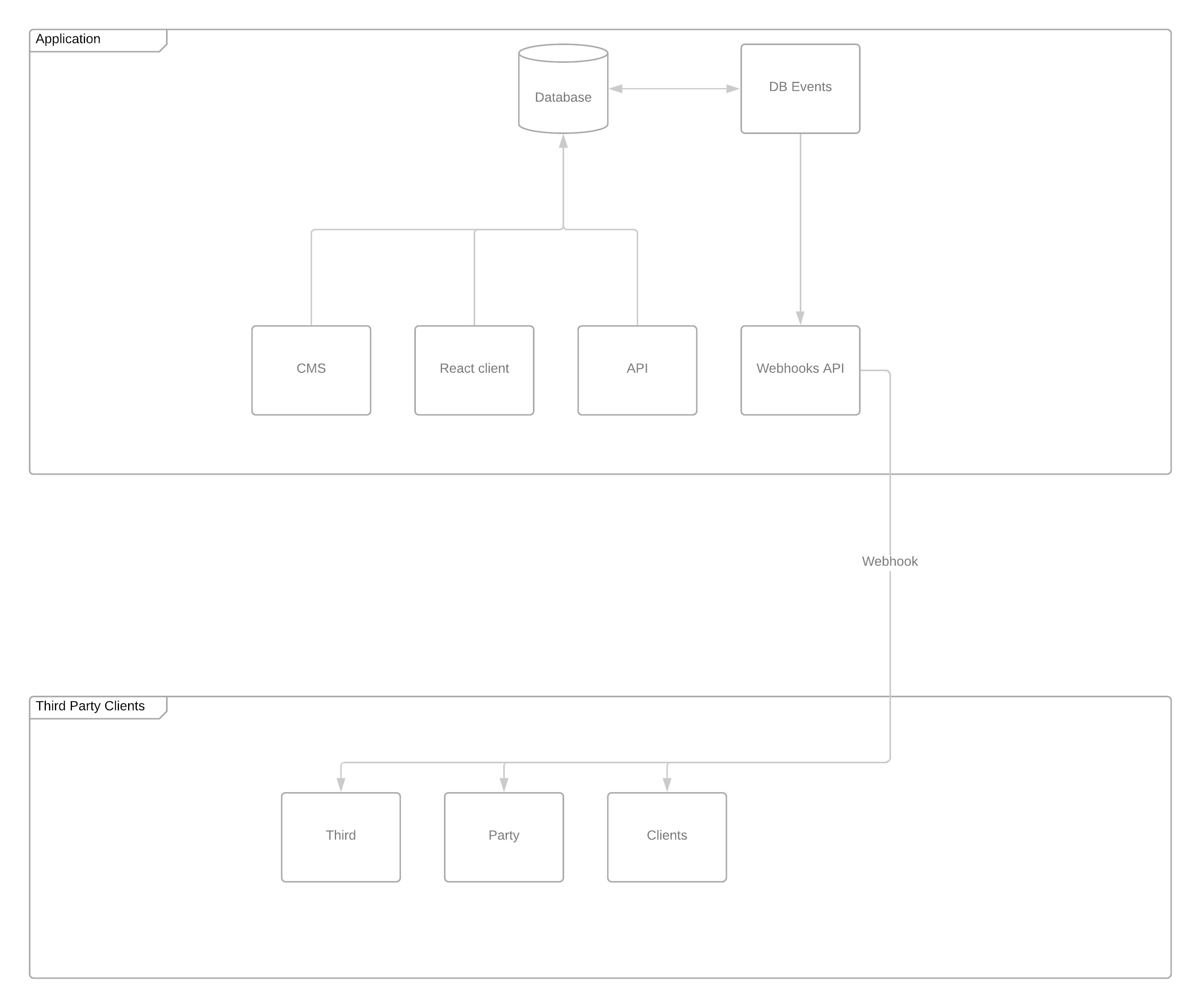
Bij een platform dat door ons ontwikkeld is draaien meerdere losse applicaties die met elkaar in verbinding staan. Naast het feit dat deze applicaties een eigen database hebben is er ook een centrale database. In de eerste opzet zijn er per applicatie een set aan API endpoints opgezet waarmee de applicaties data kunnen delen of ophalen.
Gezien de omvang van dit platform waren deze api’s al snel overbelast of liepen processen vast vanwege de hoeveelheid aan data. De import en synchronisatie processen die eigenlijk alleen de wijzigingen wilden zien, kregen ook data binnen die ongewijzigd was.
We zijn toen een onderzoek gestart naar de beste oplossing voor deze specifieke situatie. We konden natuurlijk bijhouden wat de mutaties zijn aan de hand van een datum/tijd die een import of synchronisatie gedraaid heeft. Alleen door de hoeveelheid applicaties en derde partijen die ook afhankelijk zijn van deze data viel deze optie al snel af.
Daarnaast was er de behoefte om ook smartphone apps te voeden met data en die moest zo realtime mogelijk zijn.
Webhooks to the rescue!
Omdat je direct bij de bron wilt zitten als je realtime data mutaties wilt gaan versturen zijn we op zoek gegaan naar een database oplossing. Het platform draait op een PostgreSQL database. Hier hebben we een aantal mogelijke oplossing voor kunnen vinden.
Webhooks to the rescue! De oplossing die in alle gevallen je problemen op gaat lossen is per mutatie een event. Dit kan een event zijn in de vorm van een webhook of via een ander kanaal waarmee je data direct naar een andere applicatie kan pushen. Denk aan websockets of HTTP requests.
PostgreSQL heeft een ingebouwde extensie welke ons hierbij kan helpen (pg_notify). Je hebt daar nog wel een losse tool voor nodig om pg_notify goed te laten werken, want deze kan niet direct URL’s aanroepen.
Eerst testen op 3 belangrijke aspecten
Voordat we direct een oplossing implementeren gaan we de beschikbare tools doortesten op 3 belangrijke aspecten:
• Gebruikte tool is niet outdated en wordt nog onderhouden
• Eenvoudig implementeerbaar
• Gebruikt weinig resources en kan grote hoeveelheden aan data aan
De keuze is gevallen op...
Onze uiteindelijke keuze is na het doortesten gevallen op Hasura GraphQL Engine. We hebben een eerste test gedaan met Hasura Skor, deze tool is door dezelfde partij ontwikkeld als Hasura GraphQL Engine.
De beschikbare opties waren niet voldoende en doordat Skor toegevoegd was aan de GraphQL Engine werd deze ook niet meer onderhouden. De reden dat we in het begin graag voor Skor wilden kiezen was omdat deze tool alleen database webhooks faciliteert, terwijl GraphQL Engine, zoals de naam al suggereert, een GraphQL server bevat.
Deze graphql server hoef je niet te gebruiken en kan je via de CLI uitschakelen. De web API en grafische interface van Hasura zijn echt een toegevoegde waarde.
Hasura
De keuze is dus gevallen op GraphQL Engine. Hasura heeft de ontwikkeling van Skor verder voortgezet in deze applicatie en bevat een stuk meer opties die voor ons zeer wenselijk waren.
Een kleine opsomming van deze functionaliteiten:
• Per tabel/kolom triggers instelbaar voor alle CRUD acties
• Elke trigger kan zijn eigen webhook krijgen
• Retry functionaliteit zodat gefaalde webhooks (bij deployments of onderhoud) alsnog uitgevoerd worden
• Duidelijke logging van alle webhooks inzichtelijk in een interface
Vooral de retry functionaliteiten zijn voor ons erg belangrijk, omdat we systemen willen hebben die zo min mogelijk monitoring en onderhoud nodig hebben. Als er mutaties blijven hangen door een nieuwe release of onderhoud willen we dit niet handmatig oplossen, maar moet het systeem dit vanzelf weer rechtzetten.
Het gevaar hierin is wel dat wanneer je (teveel) vertrouwt op dit soort functionaliteiten het alsnog goed fout kan gaan. Het is dus zeker wel wenselijk om toch op een bepaald niveau een stukje monitoring toe te voegen waar je drempelwaardes met notificaties voor in kan stellen.
Mocht de techniek je in de steek laten, dan kom je daar op tijd achter en kan je op tijd actie ondernemen voordat alle applicaties die afhankelijk zijn van je webhooks omvallen of sturen op verouderde informatie.
Hoe realiseren wij de implementatie
Omdat we naast onze eigen applicaties ook derden toegang willen geven tot deze data, willen we ook custom webhooks kunnen realiseren. Niet alle informatie van een bepaalde entiteit mag naar een derde partij gestuurd worden bijvoorbeeld.
Omdat we hiervoor niet allemaal losse webhooks en triggers in willen stellen die potentieel de database zwaarder kunnen belasten hebben we hier wat anders voor bedacht.
We hebben een losse applicatie ontwikkeld waar alle ingestelde webhooks binnen komen. In deze applicatie krijgen we dus ongeacht welke mutatie alles binnen waar we wat mee willen doen.
In het geval er een specifieke dataset nodig is die via webhooks bijgehouden moet worden kunnen we eenvoudig deze regels aan de applicatie toevoegen en komt deze optie beschikbaar. De clients kunnen zich dan op deze dataset abonneren en geven een URL op waar wij de data naar toe gaan pushen.
De clients die zich op datasets abonneren zijn zelf verantwoordelijk voor de implementatie van de data die zij binnen krijgen. Indien gewenst kan deze beveiligd worden met encryptie. De package die wij gebruiken voor het versturen van webhooks naar de clients is de laravel-webhook-server package.
Aandacht voor performance
Omdat er behoorlijke piekmomenten zijn in dit platform is performance een zeer belangrijk punt. Ook tijdens hogere belastingen moet alles blijven draaien en moeten de webhooks op tijd bezorgd worden bij de clients.
Om dit te realiseren hebben we meerdere queue workers draaien die de webhooks d.m.v. een wachtrij verwerken. Op deze manier voorkomen we dat er bij piekmomenten te weinig resources beschikbaar zijn, maar dat ze wel in balans zijn met de bezorgsnelheid van de data via de webhooks.
Conclusie: veel voordelen en nieuwe mogelijkheden
We gebruiken deze oplossing nu al een tijdje naar tevredenheid binnen het platform van de KNHB. Het ziet er naar uit dat deze oplossing ook bij andere klanten in gebruik genomen zal worden aangezien de vele voordelen en nieuwe mogelijkheden die nu binnen handbereik liggen.
Synchronisaties die tot voor kort nog enkele uren in beslag namen behoren nu tot het verleden.
We zien echter vaak dat veel systemen nog leunen op sterk verouderde synchronisaties die soms zelfs via FTP (csv, json of xml) bestanden klaarzetten en door externe systemen uitgelezen kunnen worden. Naast het feit dat dit soort processen niet heel veilig zijn, is deze data op het moment van generen alweer verouderd.
In de wereld van mobiele apps en PWA’s is realtime data onmisbaar. Webhooks maken dit mogelijk.
Wil je dit een keer in actie zien, of samen met ons kijken of dit voor jouw organisatie ook handig is? Kom dan een keer een kop koffie drinken!
